跨节点部署的数据并行(Data Parallel)深度神经网络(DNN)训练系统已被广泛应用于各个领域,而系统性能往往受制于工作者之间同步梯度的通信开销。Top-k稀疏化压缩是缓解通信瓶颈的最有效的方法之一。然而,传统的Top-k仍然存在性能问题:1) DNN每一层的梯度通常表示为多个维度的张量,而传统Top-k所选择的最大k个元素仅集中在所有维度中的部分维度,因此训练可能会丢失很多维度信息(称之为维度缺失),从而导致收敛性能降低;2) 传统Top-k通过对每一层的梯度元素进行全局排序(称之为单个全局排序)来执行元素选择,这可能造成GPU内核并行性较低,从而导致训练吞吐量下降。
实验室博士生明章强,硕士生周文翔,郑欣觉等在胡燏翀教授的指导下,针对以上问题,为高性能数据并行分布式DNN训练系统设计了一种全维度Top-k稀疏化压缩方案ADTopk。ADTopk对DNN的每一层梯度的所有维度进行稀疏化压缩,而不是传统的Top-k稀疏化中的某些维度。ADTopk通过基于矩阵的稀疏化方案避免了维度缺失,从而提高了收敛精度,并通过多重局部排序方案提高了GPU内核的并行性,从而提高了训练吞吐量。在ADTopk的基础上,进一步提出了一种交替压缩方案实现收敛精度和收敛速度之间的权衡,和一种有效的阈值估计算法以减小交替压缩引入传统的Top-k稀疏化造成的压缩开销。
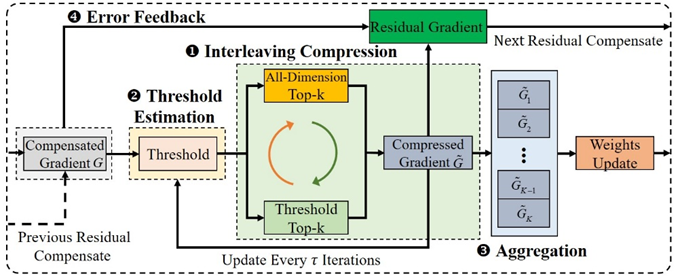
图1 ADTopk的工作流程

图2 不同训练任务上的收敛精度对比

图3 不同训练任务上的训练吞吐量对比
该研究成果以“ADTopk: All-Dimension Top-k Compression for High-Performance Data-Parallel DNN Training”为题,被HPDC 2024录用。本届会议共收到152篇投稿,共录用26篇论文,录用率约为17.1%。该研究工作得到了深圳市科技计划(JCYJ 20220530161006015)的支持。






