实验室博士邹晓敏的论文“ROWE-tree: A Read-Optimized and Write-Efficient B+-tree for Persistent Memory”、博士雷梦雅的论文“A Dynamic and Recoverable BMT Scheme for SecureNon-Volatile Memory”、硕士王霖的论文“Exploiting Parallelism in Disk Failure Recovery via Partial Stripe Repair for an Erasure-Coded High-Density Storage Server”被International Conference on Parallel Processing(ICPP 2022)正式录用。
持久性内存(Persistent Memory,PM)的出现极大地改变了计算机内存的架构和特性。B+-树是一种支持高效范围查询的平衡树,广泛地应用于存储系统中。过去的十年间,研究者设计了很多面向PM特性优化的B+-树索引。然而,现有的持久性B+-树索引的读写优化设计会相互制约,并且忽略了PM硬件本身存在的读写干扰问题,因此无法同时提供高性能的写操作和读操作。
博士生邹晓敏在王芳教授的指导下设计了面向PM的读写优化的B+-树索引结构,称为ROWE-tree。ROWE-tree的设计主要包含三个关键点。首先,ROWE-tree提出两个机制很好地权衡了读写性能:(1)自验证的插入机制,使用元素的键本身代替额外的元数据作为持久性标志以减少数据一致性开销;(2)半排序的叶子节点,采用追加写的方式执行插入操作以避免节点排序操作,但是保证CPU缓存行内的元素排序来加速叶子节点的查询。其次,鉴于真实工作负载普遍存在热点问题,ROWE-tree在DRAM中构建了一个哈希表来缓存热数据。这样做可将热数据的访问从PM迁移到DRAM中执行,极大地缓解了PM中的读写干扰问题。最后,为了应对热数据的动态变换,ROWE-tree提出一种轻量级的热数据识别和替换机制来实时追踪热数据的变换。评估结果表明,ROWE-tree相比于最先进的对比方案提升了2倍到3.86倍的查询吞吐量和1.35倍到2倍的插入吞吐量。该研究工作得到了国家自然基金(61832020、61821003)、山东省自然基金(ZR2019LZH012)、深圳科技计划(JCYJ20210324141601005)等项目的资助。
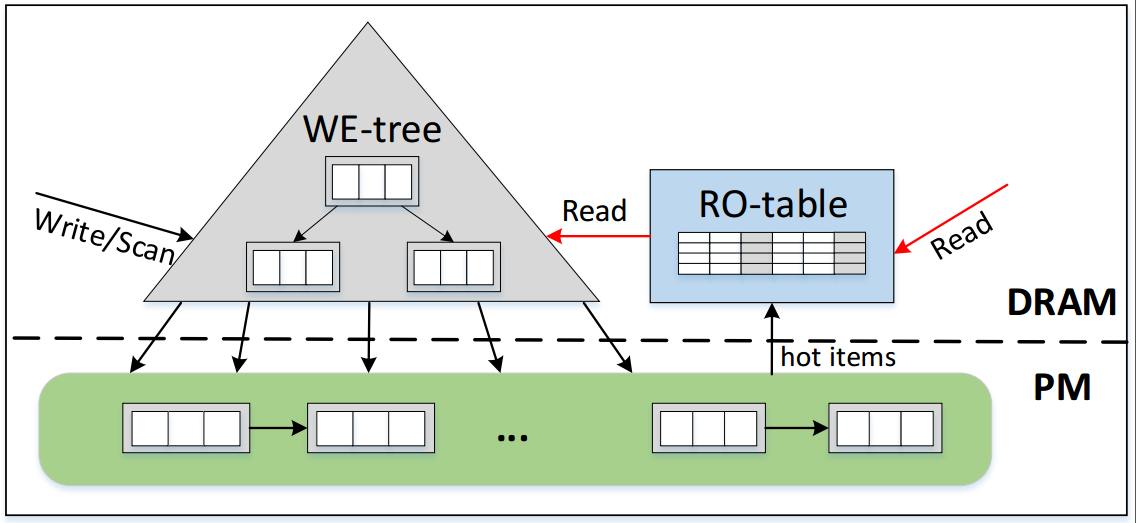
图1:ROWE-tree的整体结构图
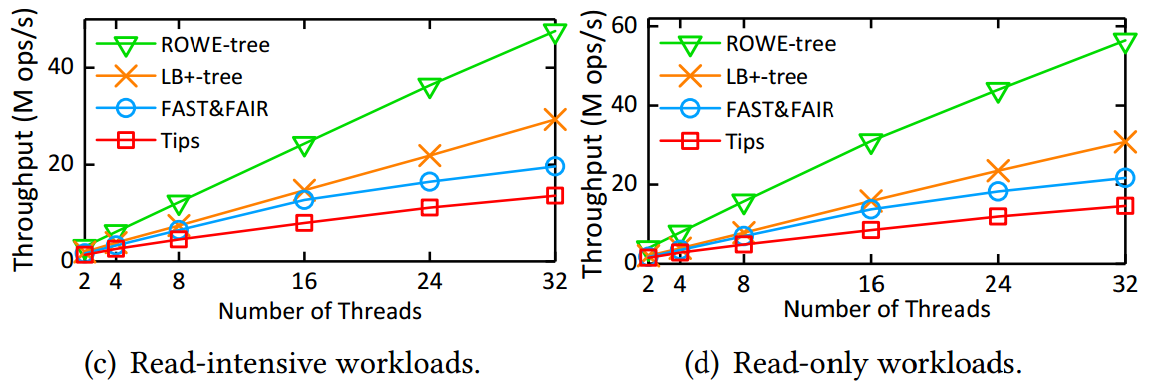
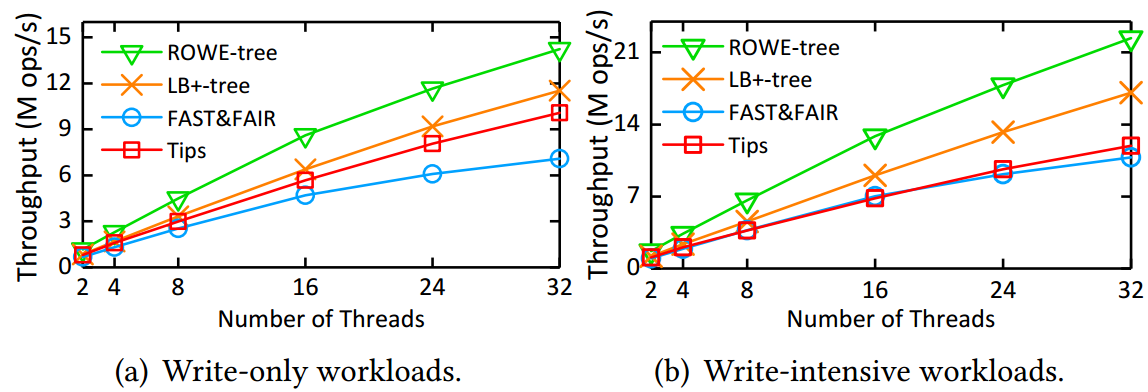
图2:ROWE-tree在YCSB工作负载下的多线程可扩展性
快速发展的新型非易失存储器件NVM在学术界和工业界都备受关注。然而,NVM也给内存安全机制的设计带来了新的挑战。非易失性存储要求在安全NVM中保障安全元数据盆景默克尔树(Bonsai MeRkle Tree, BMT)的崩溃一致性,确保系统断电后数据能正确解密、验证和恢复。这要求安全NVM系统的设计满足以下三个要求。第一,崩溃时丢失的BMT节点可以恢复到崩溃前的最新状态;第二,BMT的恢复时间不能太长,否则将降低系统的可用性;第三,BMT恢复的正确性可以验证,但这要求BMT根节点的更新需要在数据写请求的关键路径上完成,原子的BMT根节点更新大幅降低了NVM的写性能,进一步扩大了NVM的读写不对称性。
为此,实验室博士生雷梦雅,在王芳教授、冯丹教授的指导下,针对NVM系统设计实现了一种动态可恢复的BMT方案,DR-TREE。DR-TREE旨在保障低BMT更新开销和NVM写流量开销的同时,实现快速且正确的BMT恢复,保证安全NVM中的BMT崩溃一致性。DR-TREE主要有三个贡献点。首先,DR-TREE根据用户对内存写请求动态的构造BMT,以减少不必要的BMT层次,降低了BMT根的更新开销。其次,DR-TREE提出了一种BMT的批量更新方法,该方法利用内存写请求的空间局部性减少了BMT的冗余更新,进一步降低了BMT根的更新开销。最后,DR-TREE提出了一种延迟BMT恢复方法,该方法利用BMT的叶子可重构性和根节点的可验证性,以极低NVM写流量开销实现了快速的系统恢复。结果表明,DR-TREE可以在5毫秒内实现BMT恢复,无论是在性能还是写入流量方面,与最新的解决方案相比,DR-TREE都有较大的优化。该研究工作得到了国家自然基金(61832020、61821003)和深圳科技计划(JCYJ20210324141601005)项目的资助。
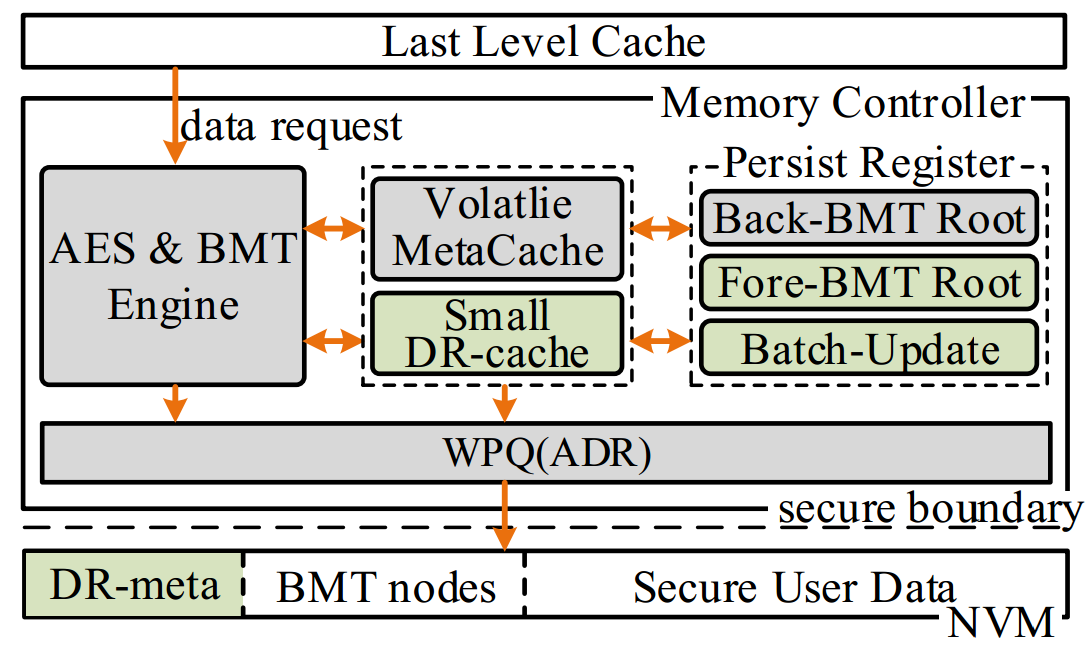
图3:DR-TREE的系统结构图
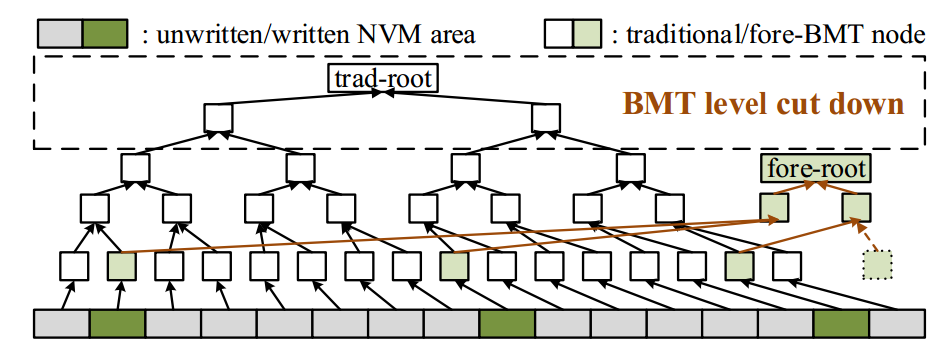
图4:DR-TREE随应用写请求逐步构建BMT以降低BMT层次
近日,高密度存储服务器(配备有很多磁盘的服务器)开始得到广泛的关注。因为其可以大幅缩减数据中心的物理规模,从而使得能耗成本、冷却成本和管理成本的大幅下降。但是磁盘故障的频率也随着磁盘数量的上升而上升。因此如何保障数据可靠性是一个重要的话题。纠删码是目前较为流行的一种提供数据可靠性的方案。应用最为广泛的Reed-Solomon编码可以将k个数据块编码为一个包含n个编码块(k个数据块+m个校验块)的条带。这n个编码块中的任意k个块都可以修复其余的块。
纠删码一直面临修复放大的难题,即需要读取k个块才可以修复出1个块。这在分布式存储系统上会造成网络拥塞的问题。目前已经有很多研究致力于解决该问题(例如PPR,RP,PPT等)。但是在高密度存储服务器上,由于传输依靠的是总线,因此传输很难再称为瓶颈。但是当很多的磁盘同时向内存传输数据时,内存就会成为限制数据修复的瓶颈。高密度存储服务器面临的问题是:当有数量众多的磁盘同时向内存传输数据时,单个机器内存资源的有限性就成为了数据修复性能的瓶颈。如何设计修复算法来提高高密度存储服务器上的数据修复效率就成为了一个亟待解决的问题。
信息存储及应用实验室硕士生王霖、杜谦,在胡燏翀教授的指导下,设计了一种能够提高内存资源利用率的并行修复算法。通过对传统的纠删码高效修复算法的规律和思想进行归纳总结,我们得出纠删码修复具有的两种并行性——条带内并行性和条带间并行性。我们对这两种并行性进行了观察分析,挖掘出了这两种并行性之间的三个关系,并分析出这两种并行性对修复性能的影响。基于这些观察分析,我们提出了三个面向单磁盘故障的数据修复算法以及一个针对多磁盘故障的数据修复算法。最终实验结果显示,我们的算法可以最多可以将单磁盘故障的数据修复时间降低71.7%。多磁盘数据修复时间最多也能降低52.5%左右。该研究工作得到了国家自然科学基金(No.61872414)项目的资助。
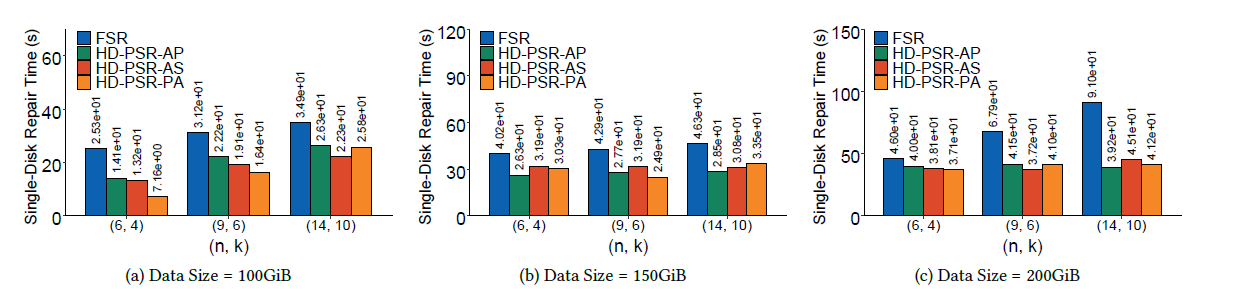
图5:单磁盘故障数据修复时间对比
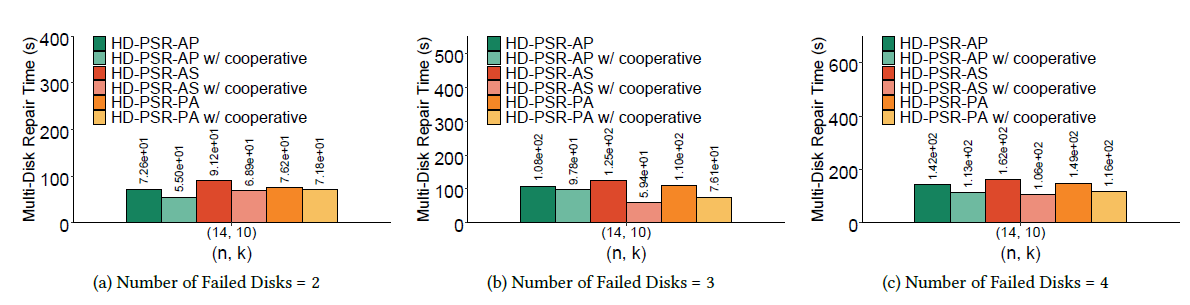
图6:多磁盘故障数据修复时间对比






